Whole document tree
|
|
The big picture
The previous chapters in this Reference Guide have described applications that use the Berkeley DB Access Methods for fast data storage and retrieval. The applications we describe here and in subsequent chapters are similar in nature to the Access Method applications, but they are also fully recoverable in the face of application or system failure.
Application code that only uses the Berkeley DB Access Methods might appear as follows:
switch (ret = dbp->put(dbp, NULL, &key, &data, 0)) {
case 0:
printf("db: %s: key stored.\n", (char *)key.data);
break;
default:
dbp->err(dbp, ret, "dbp->put");
exit (1);
}The underlying Berkeley DB architecture that supports this is:
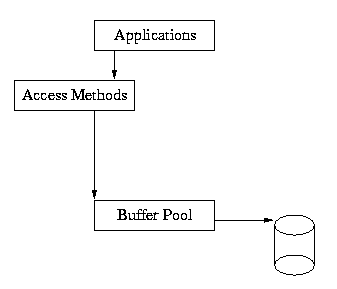
As you can see from this diagram, the application makes calls into the Access Methods, and the Access Methods use the underlying shared memory buffer cache to hold recently used file pages in main memory.
When applications require recoverability, then their calls to the Access Methods must be wrapped in calls to the transaction subsystem. The application must inform Berkeley DB where to begin and end transactions, and must be prepared for the possibility that an operation may fail at any particular time, causing the transaction to abort.
An example of transaction protected code might appear as follows:
retry: if ((ret = txn_begin(dbenv, NULL, &tid)) != 0) {
dbenv->err(dbenv, ret, "txn_begin");
exit (1);
}
switch (ret = dbp->put(dbp, tid, &key, &data, 0)) {
case DB_LOCK_DEADLOCK:
(void)txn_abort(tid);
goto retry;
case 0:
printf("db: %s: key stored.\n", (char *)key.data);
break;
default:
dbenv->err(dbenv, ret, "dbp->put");
exit (1);
}
if ((ret = txn_commit(tid)) != 0) {
dbenv->err(dbenv, ret, "txn_commit");
exit (1);
}
In this example, the same operation is being done as before, however, it is wrapped in transaction calls. The transaction is started with txn_begin, and finished with txn_commit. If the operation fails due to a deadlock, then the transaction is aborted using txn_abort, after which the operation may be retried.
There are actually five major subsystems in Berkeley DB, as follows:
- The Access Methods
- The Access Method subsystem provides general-purpose support for creating and accessing database files formatted as Btrees, Hashed files, and Fixed- and Variable-length records. These modules are useful in the absence of transactions for applications that need fast, formatted file support. See DB->open and DB->cursor for more information. These functions were already discussed in detail in the previous chapters.
- The Memory Pool
- The memory pool subsystem is the general-purpose shared memory buffer pool used by Berkeley DB. This is the shared memory cache that allows multiple processes and threads within processes to share access to databases. This module is useful outside of the Berkeley DB package for processes that require portable, page-oriented, cached, shared file access.
- Transactions
- The transaction subsystem allows a group of database changes to be treated as an atomic unit so that either all of the changes are done, or none of the changes are done. The transaction subsystem implements the Berkeley DB transaction model. This module is useful outside of the Berkeley DB package for processes that want to transaction protect their own data modifications.
- Locking
- The locking subsystem is the general-purpose lock manager used by Berkeley DB. This module is useful outside of the Berkeley DB package for processes that require a portable, fast, configurable lock manager.
- Logging
- The logging subsystem is the write-ahead logging used to support the Berkeley DB transaction model. It is largely specific to the Berkeley DB package, and unlikely to be useful elsewhere except as a supporting module for the Berkeley DB transaction subsystem.
Here is a more complete picture of the Berkeley DB library:
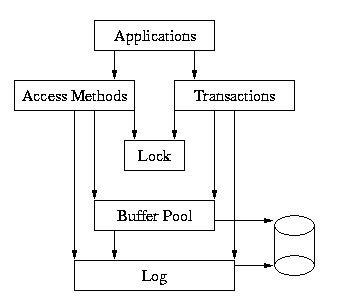
In this example, the application makes calls to the Access Methods and to the transaction subsystem. The Access Methods and transaction subsystem in turn make calls into the Buffer Pool, Locking and Logging subsystems on behalf of the application.
While the underlying subsystems can each be called independently. For example, the Buffer Pool subsystem can be used apart from the rest of Berkeley DB by applications simply wanting a shared memory buffer pool, or the Locking subsystem may be called directly by applications that are doing their own locking outside of Berkeley DB. However, this usage is fairly rare, and most applications will either use only the Access Methods, or the Access Methods wrapped in calls to the transaction interfaces.
|
|